GASを使えば1行でGoogle翻訳が可能!
n-mukineer
エヌローグ

こんにちは、えぬ(@nmukineer)です!
今回は、Google Cloud の Vision APIを使って、ブログのサムネイル画像からテキストを抽出するGASスクリプトを書いてみました。
Vision AIとVision APIがあってややこしい…
Vision APIを利用するにあたり、サービスの立ち位置を整理しておきましょう。
Vision AIとVision APIは、こちらの図のような関係性となっています。
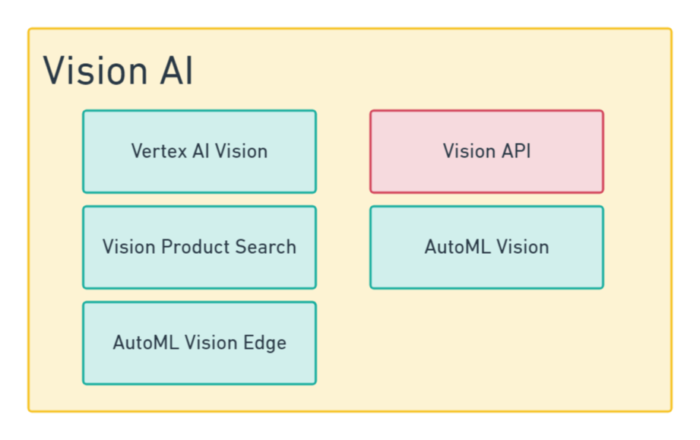
つまり、Vision AIという括りの中に、1つのサービスとしてVision APIが提供されているという構造となっています。
Vision APIは、Googleが提供する画像解析のためのAPIサービスです。
画像から顔や企業ロゴを検出したり、画像から特徴的な建造物を抽出するなど、さまざまな機能があるようです。
今回はその中でも、TEXT_DETECTIONという、画像からテキストを抽出するAPI(光学式文字認識:OCR)を使ってみました。
Vision APIは、最初の1,000ユニット(1カ月あたり)は無料となっています。さらに、最初は300ドル分の無料クレジット(90日間有効)をもらえるので、相当ヘビーユースしない限りは課金の対象にならないかと思います!
Vision AIを使えるようにすることで、その子サービスであるVision APIを利用することが可能になります。利用開始までの操作は以下の手順で行います。
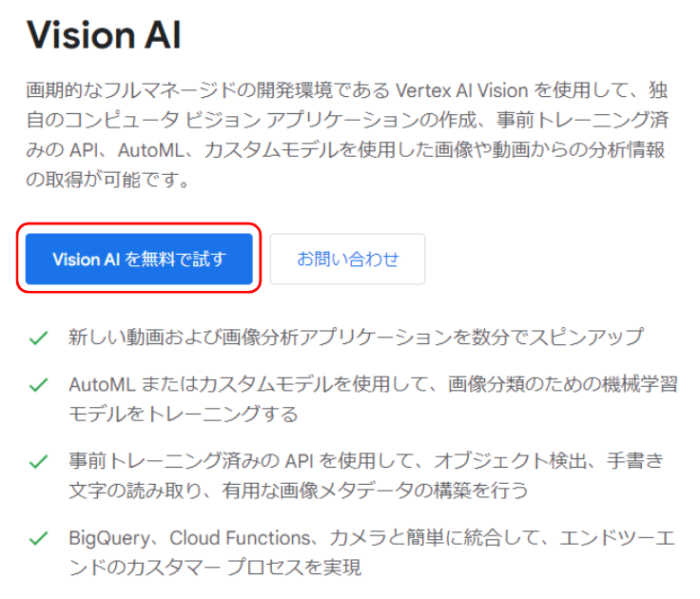
国籍、利用目的、利用規約へのチェックを入れ、「続行」をクリックします。
クレジットカード情報を入力し、「無料トライアルを開始」をクリックします。

4つのアンケートに答えるポップアップが出ますので回答します。(ここは「閉じる」を押してスキップすることも可能です)

Google CloudのCloud Vision APIページに行き、「有効にする」をクリックしてAPIを有効化します。

なお、事前にGoogle Cloudのプロジェクト作成が必要となります。プロジェクト作成方法については以下の記事を参考にしてみてください。

Google Cloudのプロジェクトページに行き、「APIとサービス」から「認証情報」をクリックします。
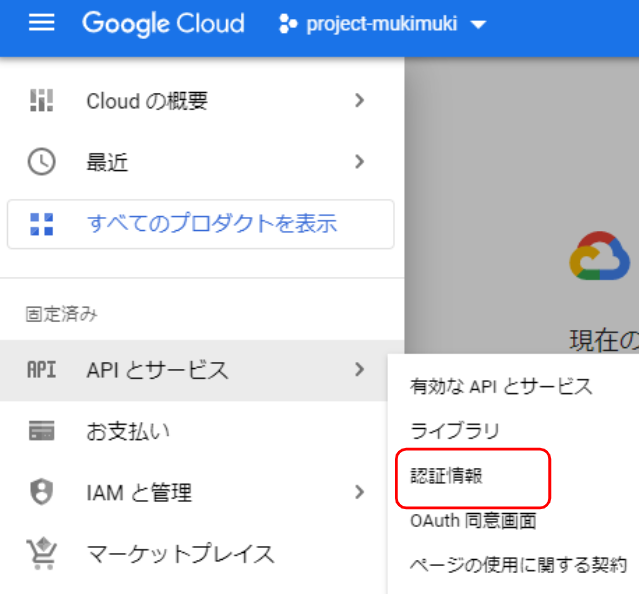
「認証情報を作成」から、「APIキー」を選択します。

APIキーが作成されますので、コピーしておきましょう。
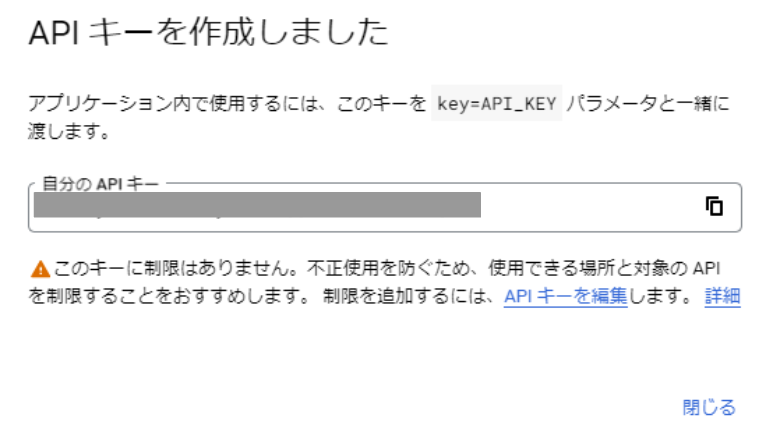
GASのプロジェクトとGCPのプロジェクトの紐づけを行います。STEP6でAPIキーを作成しておいたGCPプロジェクトを、今回作成するGASに紐づけます。
紐づけ方法については以下の記事に書いてありますので参考にしていただければ幸いです。

以上でVision APIがGASで使えるようになりました。
ここから実際にGASでスクリプトを書いていきます!
画像からテキストを抽出する手順は、
という流れとなります(画像のURLがダイレクトに取得できる場合は、画像を保存する必要はありません)。
まずは、Google Driveに画像を保存するためのフォルダを作成します。
作成したフォルダに、テキストを抽出したい画像を保存していきましょう。
今回は試しということで、これまでのブログ記事に使用した以下の3つの画像を使用したいと思います。


1で保存した画像のIDを取得します。手動で取得する方法と、GASスクリプトを使って取得する方法どちらも紹介します。
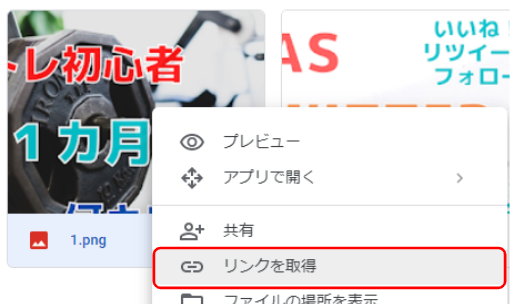
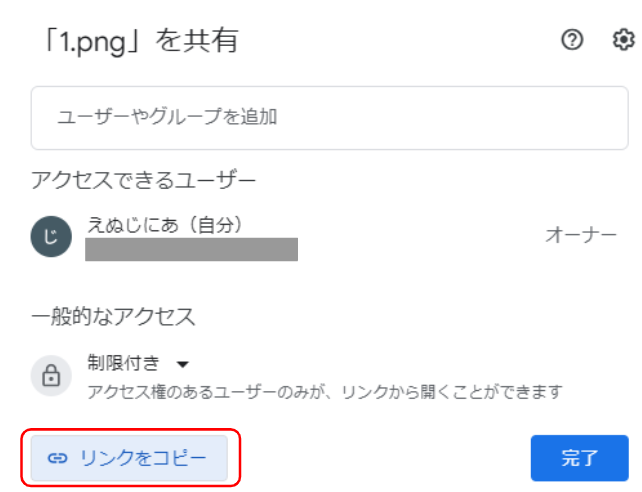
STEP2でコピーしたリンクは以下のようになっています。
https://drive.google.com/file/d/ファイルID/view?usp=share_link
ここからファイルIDを取得することができます。
ブラウザで、画像が保存されているGoogle Driveのフォルダページを開きます。
その状態でブラウザのURL欄を確認してください。
https://drive.google.com/drive/folders/フォルダID

このように、フォルダIDがURLに含まれいていますので、「フォルダID」の部分をコピーしてGASで使用できるようにしておきましょう。
以下のスクリプトは、フォルダIDを指定するとその中にあるファイルについて、
を抽出することができます。
const FOLDER_ID = "ここにフォルダIDを入れて下さい";
function getFileInfo() {
const imageFolder = DriveApp.getFolderById(FOLDER_ID);
const imageFiles = imageFolder.getFiles();
const fileInfo = [];
while(imageFiles.hasNext()) {
const file = imageFiles.next();
const fileName = file.getName();
const fileId = file.getId();
const fileUrl = file.getUrl();
console.log(`ファイル名:${fileName}, ファイルID:${fileId}, URL:${fileUrl}`)
fileInfo.push({
name: fileName,
id: fileId,
url: fileUrl
})
}
return fileInfo;
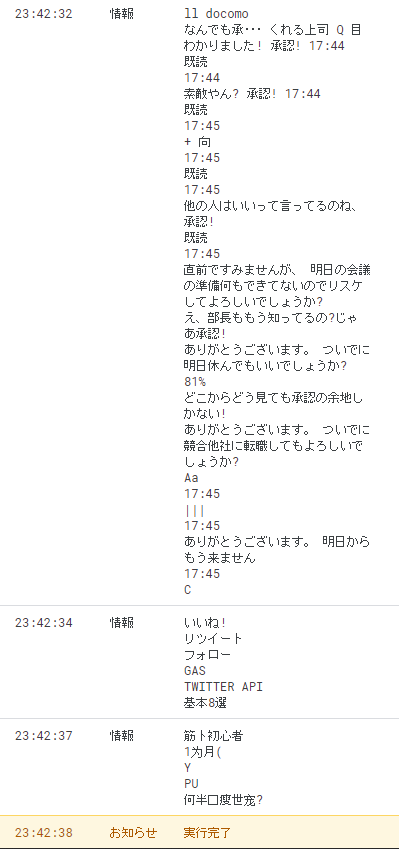
}実行すると、以下のようにログに出力されます。

const VISION_API_URL = "https://vision.googleapis.com/v1/images:annotate";
const API_KEY = "ここにAPIキーを入れてください";
// 実行する関数
function main() {
const fileInfo = getFileInfo();
console.log(fileInfo);
fileInfo.forEach(file => {
const text = extractTextsFromImage(file.id);
console.log(text);
})
}
// 画像URLからテキストを抽出する関数
function extractTextsFromImage(fileId) {
const imageData = DriveApp.getFileById(fileId).getBlob().getBytes();
const payload = {
"requests": [
{
"image" : {
"content": Utilities.base64Encode(imageData)
},
"features": [
{
"type": "TEXT_DETECTION"
}
]
}
]
}
const response = JSON.parse(UrlFetchApp.fetch(VISION_API_URL+`?key=${API_KEY}`, {
'method': 'POST',
'contentType': 'application/json; charset=utf-8',
'payload': JSON.stringify(payload)
}));
return response.responses[0].fullTextAnnotation.text;
}
新たにGoogle Spreadsheetを作成し、スプレッドシートIDを取得しておきます(スプレッドシートIDは、2で紹介した画像のIDの手動での取得方法と同じです)。
スプレッドシートのシートに、名前を付けておきましょう。ここでは、「extractedTexts」という名前としました。
const API_KEY = PropertiesService.getScriptProperties().getProperty('API_KEY');
const FOLDER_ID = PropertiesService.getScriptProperties().getProperty('FOLDER_ID');
const SPREADSHEET_ID = PropertiesService.getScriptProperties().getProperty('SPREADSHEET_ID');
const VISION_API_URL = "https://vision.googleapis.com/v1/images:annotate";
// 実行する関数
function main() {
const fileInfo = getFileInfo();
console.log(fileInfo);
fileInfo.forEach(file => {
const text = extractTextsFromImage(file.id);
appendRow([file.name, file.url, text]);
});
}
// スプレッドシートに1行追加する関数
function appendRow(row) {
const activeSheet = SpreadsheetApp.openById(SPREADSHEET_ID);
const sheet = activeSheet.getSheetByName('extractedTexts');
sheet.appendRow(row);
}
// 画像URLからテキストを抽出する関数
function extractTextsFromImage(fileId) {
const imageData = DriveApp.getFileById(fileId).getBlob().getBytes();
const payload = {
"requests": [
{
"image" : {
"content": Utilities.base64Encode(imageData)
},
"features": [
{
"type": "TEXT_DETECTION"
}
]
}
]
}
const response = JSON.parse(UrlFetchApp.fetch(VISION_API_URL+`?key=${API_KEY}`, {
'method': 'POST',
'contentType': 'application/json; charset=utf-8',
'payload': JSON.stringify(payload)
}));
return response.responses[0].fullTextAnnotation.text;
}
// 画像ファイル情報を取得する関数
function getFileInfo() {
const imageFolder = DriveApp.getFolderById(FOLDER_ID);
const imageFiles = imageFolder.getFiles();
const fileInfo = [];
while(imageFiles.hasNext()) {
const file = imageFiles.next();
const fileName = file.getName();
const fileId = file.getId();
const fileUrl = file.getUrl();
console.log(`ファイル名:${fileName}, ファイルID:${fileId}, URL:${fileUrl}`)
fileInfo.push({
name: fileName,
id: fileId,
url: fileUrl
})
}
return fileInfo;
}
今回は、画像からテキストを抽出するGASスクリプトを書いてみました。さらに、その結果をスプレッドシートに転記することも試してみました。
結果としては、背景がごちゃごちゃしているとうまく文字が拾えなかったりするようでしたが、おおむね抽出できていたように思います。手書きの文字などでも試してみたいですね。
最後までお読みいただきありがとうございました!





